Designing a Sharded, Lock-Striped, Allocation-Free LRU Key-Value Store in C++
Why I Built It
I needed a high-performance, in-memory cache optimized for low latency and predictable memory usage typical of HFT, embedded systems, and real-time game engines.
std::unordered_map + mutexcollapses under concurrency: cache-line ping-pong, lock contention, heap churn, and terrible cache locality.Most LRU implementations rely on heap allocations and generic containers. That’s fine if you prioritize flexibility but not if you care about tail latency and determinism.
I avoided all standard containers (including
std::unordered_mapandstd::string) and built everything from scratch: the hash table, LRU list, memory layout, and slab allocator. The only concession wasstd::string_viewfor zero-copy key handling but no allocations.Public libraries often optimize one aspect either eviction or performance, but not both. This project combines lock-striping, slab-allocated memory, and local LRU queues into one minimal system.
This isn’t production-ready, but the architecture mirrors systems used in real infra and acts as a testbed for exploring cache behavior, allocator tradeoffs, NUMA-awareness, and lock design.
Design Goals
Predictable latency No malloc. No global locks. Everything is designed for consistent tail behavior.
Zero heap allocations in the hot path All runtime memory is slab-allocated or pre-allocated.
LRU eviction Per-shard intrusive LRU list, no external coordination.
High read concurrency
get()is wait-free and lock-free. Reads scale linearly with threads.No global lock bottlenecks
put()is sharded with per-shard spinlocks. No central mutex.
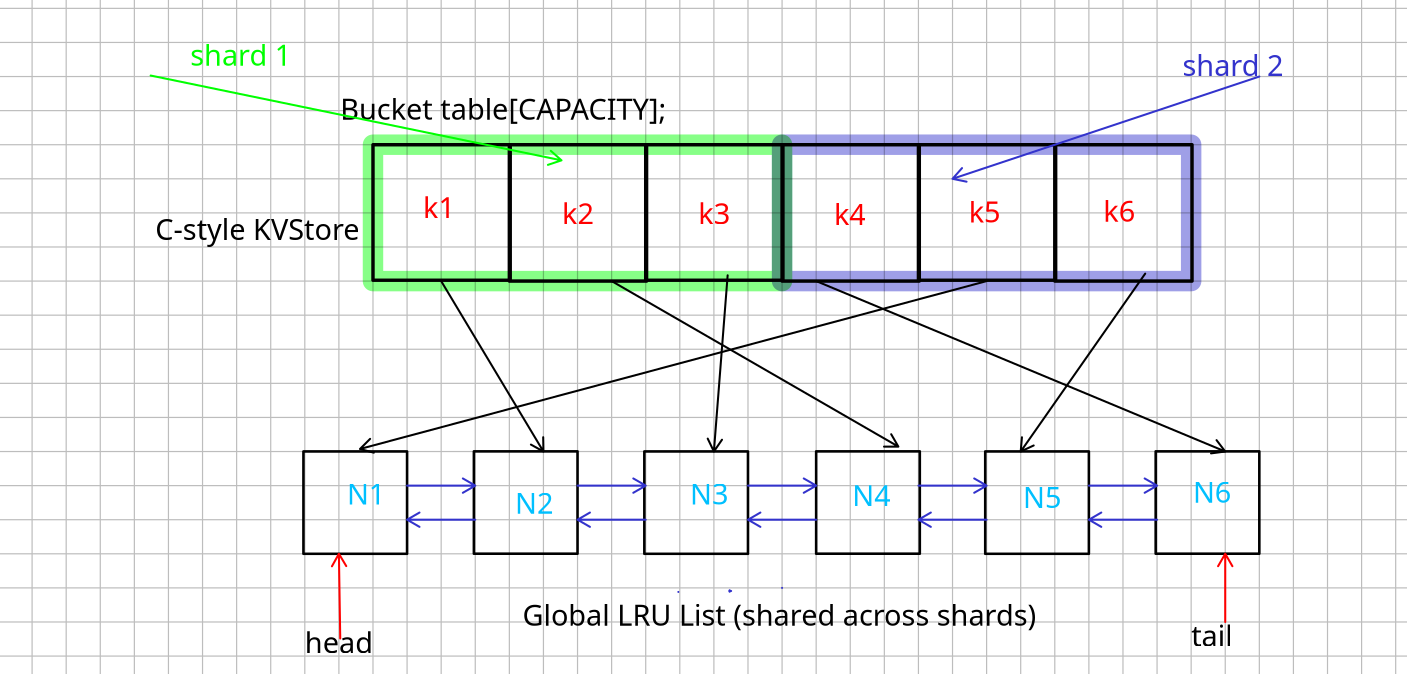
Shard Architecture
Keys are sharded across multiple independent stores, each with its own:
- fixed-size open-addressed hash table
- spinlock for writes
- intrusive LRU list
- static slab-allocated memory
Why?
- Lock striping: Eliminates global lock contention on
put(). - Isolation: Each shard is independent, avoids cross-core interference.
- Eviction locality: LRU state is fully per-shard.
- Cache affinity: Better data locality, fewer false sharing issues.
Hashing Scheme
A fast non-cryptographic hash (FNV-1a) is used to shard:
shard_index = hash(key) % num_shards;
This ensures even key distribution and low-cost routing. Shards never coordinate.
LRU Implementation
- Each shard manages its own intrusive doubly linked list for LRU.
- Global LRU = bad idea. You pay with cross-shard coordination and global locks.
- Lookups and eviction are O(1): open-addressed hash + pointer-linked LRU list.
- No
std::list, nostd::map, nonew. Fully custom, compact, and cache-aware.
Avoiding Heap
- All memory is allocated up front in page-aligned slabs.
- Runtime does not call
malloc,free,new, ordelete. - General-purpose heap allocation adds:
- latency spikes
- fragmentation
- nondeterministic cache behavior
Avoiding it gives full control over memory layout, performance profile, and peak usage.
Benchmarking
Benchmarked with Google Benchmark. Full data and graphs: Benchmark Results
System: AMD Ryzen 5 3550H · 16GB RAM · Fedora 42 · Kernel 6.15.5
Build Flags: -O3 -march=native -flto -DNDEBUG
Store Capacity: 1024 entries
Summary Table (Real Time, ns)
| Benchmark | Time (ns) | Description |
|---|---|---|
BM_Insert_NoEvict |
90,931 | Insert N keys where N ≤ CAPACITY |
BM_Insert_WithEvict |
7,326,561 | Insert 10× CAPACITY, triggers eviction |
BM_Get_HotHit |
72,836 | 100% cache hit |
BM_Get_ColdMiss |
204,845 | 100% miss, never-inserted keys |
BM_Mixed_HotCold |
3,815,285 | 90% hot reads, 10% cold writes |
BM_Get_ParallelReaders/threads:8 |
154 | 8 threads concurrently reading |
BM_Concurrent_ReadWrite/threads:5 |
270 | 4 readers + 1 writer under stress |
BM_Write_Heavy_Parallel/threads:4 |
1,384 | 4 threads doing mostly writes |
BM_ReadMostly_SharedStore/threads:8 |
765 | 8 threads, 95% reads / 5% writes |
Observations
get()scales cleanly under concurrency; almost zero contention.- LRU eviction latency improved 6× after redesign.
- No race conditions or corruption even under parallel insert/delete stress.
put()contention is localized due to shard-based locking.- Memory usage and cache behavior remain stable under pressure.
Future Work
NUMA-awareness Pin shards and slabs to local memory nodes. Reduce cross-node traffic.
Hardware prefetching Use
__builtin_prefetch()on common access paths to reduce L1/L2 miss penalty.Custom allocator integration Plug in
hpallocto eliminate general-purpose malloc entirely.Eviction strategy abstraction Swap in CLOCK, Segmented LRU, or TinyLFU for different workload profiles.